
Autonomous Off-road driving | Learning-Based Navigation
Autonomous off-road driving, a key challenge in robotics, has broad applications in agriculture, mining, search and rescue, exploration, and defense. While off-road has many similarities in urban areas, a major difference is a lack of an obstacle/no obstacle dichotomy. That is, in off-road scenarios, not all objects are obstacles, and identifying which objects are traversable in a reliable way is critical.
Our research covers a wide range of topics that aim at expanding the robot’s capability as well as improving its robustness in challenging environments. We utilize modern machine learning techniques while eliminating the exhausting hand-labeling process. In specific, we explore self-supervised learning and learning-from-demonstration to understand the terrain traversability cost and vehicle dynamics from large-scale interaction data, online adapt the cost and dynamics model to overcome the out-of-distribution failures. Our system doesn’t require human labeled data, instead, it relies on its own experiences of interacting with the environment, while being aware of the uncertainty in each model, and online adapt the model in novel situations. We will explain our design philosophy in more detail and introduce the key components in the following sections.
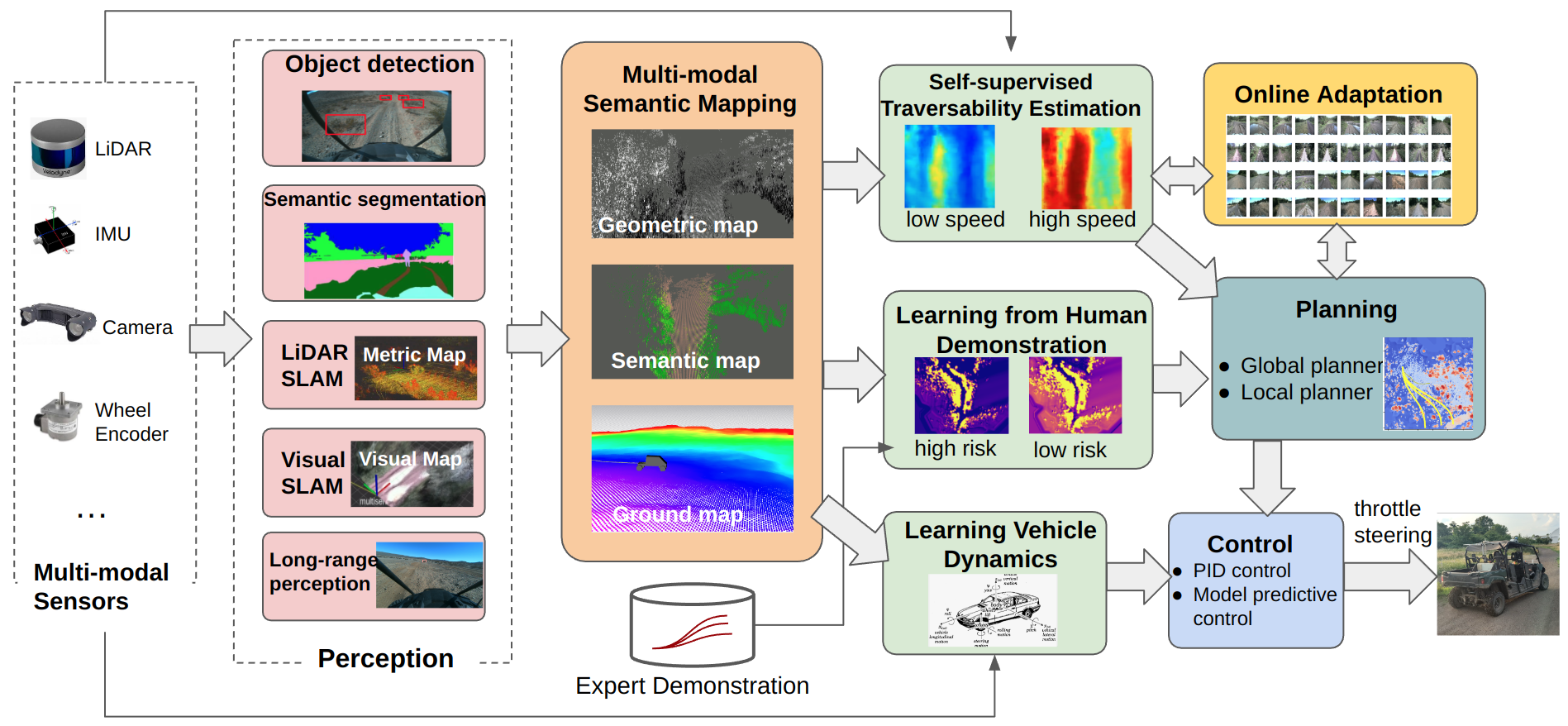
Our Design Philosophy: Moving to a No-Hand Labeling Paradigm
Identifying objects with object detection and semantic segmentation and then avoiding them has been a proven strategy for urban driving. As such, a common approach for off-road driving is to identify terrain regions such as trails, rocks and grass using semantic segmentation, assign them costs, and use a planner to avoid the high-cost semantic classes.
However, there are some limitations to this approach that are unique to the off-road driving case:
- Intra-class variance: Not all objects in the same semantic class should receive the same cost. For instance, in the following Figure, the terrains inside the two boxes are of similar height and ground color. Although both are segmented as mud, humans can perceive the green part is safer than the red part.
- Assigning costs to classes is difficult: While a general ordering of classes is easy to obtain (i.e. trails should be low-cost, rocks should be high-cost), the exact cost values that the downstream planner uses are heuristically determined.
- Semantic segmentation labels are time-consuming: It takes minutes to label a single image frame for semantic segmentation. Furthermore, the boundaries between semantic classes are not well-defined.

These limitations result in that designing an off-road driving system is a time-consuming, laborious process that involves months of data labeling, design and field testing. Furthermore, these systems are often overfit to a given environment. As such, this process often needs to be repeated for new environments (e.g. moving from a forest to a desert).
In order to design methods that scale more effectively, we have been developing methods that can learn how to navigate effectively without using human labels.
Hardware System and Dataset


Our ATV is equipped with a multi-modal sensor payload, which includes LiDARs, cameras, IMUs, shock travel sensors, wheel encoders and more. We have released two large-scale off-road driving datasets: TartanDrive and TartanDrive-V2.
To battle the extreme conditions such as smoke, fog and darkness, we added thermal cameras to the sensor payload. New data will be released.

3D Multi-modal Semantic Mapping for High-Speed Off-road Driving
Reliable and high-speed autonomous off-road driving has the potential to better connect previously hard-to-access areas that have few paved roads. While there have been wide efforts over the past decade towards building autonomous off-road agents, most are relatively slow due to their limited sensing range.
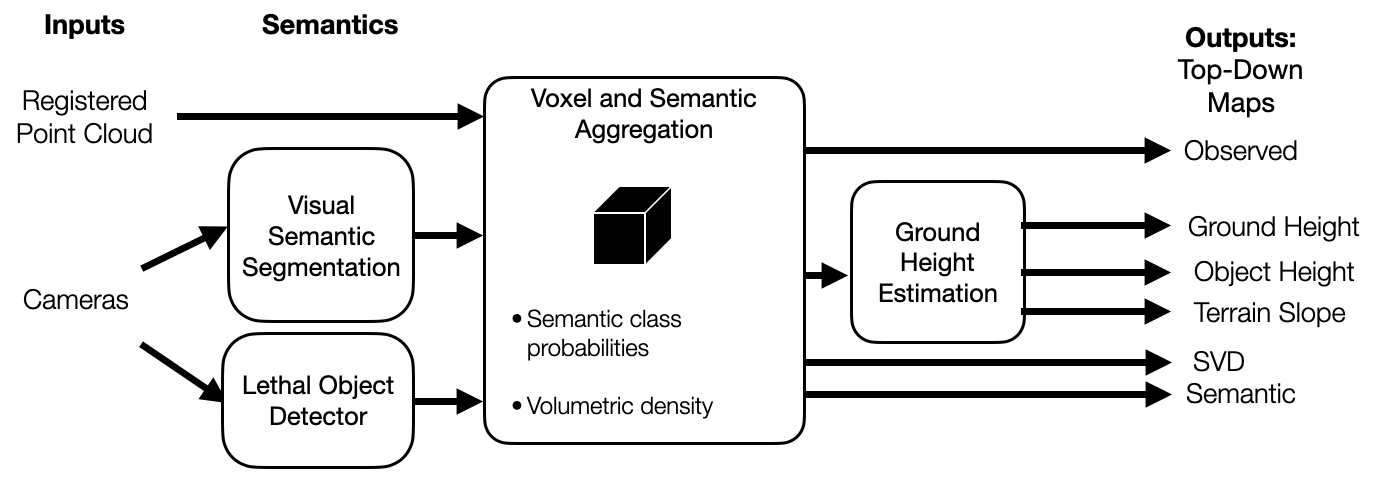
We therefore develop a 3D multi-modal semantic mapping module capable of delivering long-range and fine grained traversability information for intelligent high-speed off-road driving.
We derive 3 main requirements of high-speed off-road driving that drive our design decisions:
- Off-road environments are incredibly 3-dimensional: Vehicles need to navigate extreme slopes and go through overhangs that may otherwise be marked as obstacles.
- 3D Voxel Map Representation, Denoised ground height estimation
- Safe high-speed driving requires a large sensing range: Laser range sensors (LiDARs) are often used for off-road sensing, however many environmental features important to determining traversability are difficult to differentiate beyond short range (< 30m) due to sparsity in sensing.
- Use camera + LiDAR sensing for accurate long-range information
- Intelligent driving requires fine-grained information on terrain traversability: Using an occupancy-only traversability measure is insufficient as areas of similar heights can have different traversability: rock vs. traversable grass.
- Augment geometric maps with semantic terrain information
Our resulting semantic mapping module has been tested in diverse environments: from highly-vegetated forests, extreme sloped hills and desert with hidden rocks. In all environments, our module has delivered accurate, long-range information for high-speed driving.
The base of our 3D multi-modal mapping is voxels. All 3D information coming from different perception sensors and components are processed and stored in a voxel. The data structure of the voxel map is composed of 2D grid cells (XY) where each cell contains a certain number of voxels (Z). The foundation of the voxel map is a lidar point cloud. Each lidar point is processed and stored in a corresponding voxel. Ground elevation is estimated based on the lowest reliable voxel point information in a 2D cell. In ground elevation estimation, Random Markov Field (MRF) is applied in order to more accurately depict ground changes. With the help of ground elevation map, height map and slope map(s) are generated. Besides, with all voxel point information in a cell, a singular value decomposition (SVD) map is generated. For semantics, after an image is inferenced with a trained visual semantic model, the corresponding lidar point cloud is projected onto the predicted image. The successfully projected points are assigned with the image pixel visual semantic information. Next, the visual semantic point cloud populates the voxel map and updates semantic information in a voxel. Finally, 3D voxel semantic information is projected onto 2D grid cells in order to generate a semantic map.
For semantics, after an image is inferenced with a trained visual semantic model, the corresponding lidar point cloud is projected onto the predicted image. The successfully projected points are assigned with the image pixel visual semantic information. Next, the visual semantic point cloud populates the voxel map and updates semantic information in a voxel. Finally, 3D voxel semantic information is projected onto 2D grid cells in order to generate a semantic map.
Additionally, we leverage features from visual foundation models (VFMs) such as DinoV2 to give us semantic-level features without requiring semantic annotations for given environments.

Terrain Analysis through Self-Supervised Learning
Certain characteristics of the terrain, such as slope, irregularities in height, the deformability of the ground surface, and the compliance of the objects on the ground, affect the dynamics of the robot as it traverses over these features. While these interactions are easily captured by proprioceptive sensors, such as the linear acceleration experienced by the robot, this requires the robot to have already driven over these features to sense them. Sensors such as cameras and lidars are able to capture the visual and geometric characteristics of the terrain, but these alone are not good predictors of robot-terrain interactions without grounding them in what the robot actually feels while driving over the terrain.
Previous approaches for off-road traversability have focused on representing visual and geometric information as occupancy maps, or learning semantic classifiers from labeled data to map different terrains to different costs in a costmap. Yet, this abstracts away all the nuance of the interactions between the robot and different terrain types. Under an occupancy-based paradigm, concrete, sand, and mud would be equally traversable since they are terrain types with low height, whereas tall rocks, grass, and bushes would be equally non-traversable since they are taller features of the terrain. In reality, specific instances of a class may have varying degrees of traversability (e.g. some bushes are traversable but not all).
What we are really interested in capturing is roughness in traversability as the vehicle experienced it, rather than capturing the appearance or geometry of roughness. For instance, a point cloud of tall grass might appear rough, but traversing over this grass could still lead to smooth navigation if the terrain under the grass is smooth.
In our ICRA 2023 paper “How Does It Feel? Self-Supervised Costmap Learning for Off-Road Vehicle Traversability”, we propose a self-supervised method that predicts costmaps that reflect nuanced terrain interaction properties relevant to ground navigation. We approach this problem by learning a mapping from rich exteroceptive information and robot velocity to a continuous traversability cost derived from IMU data.
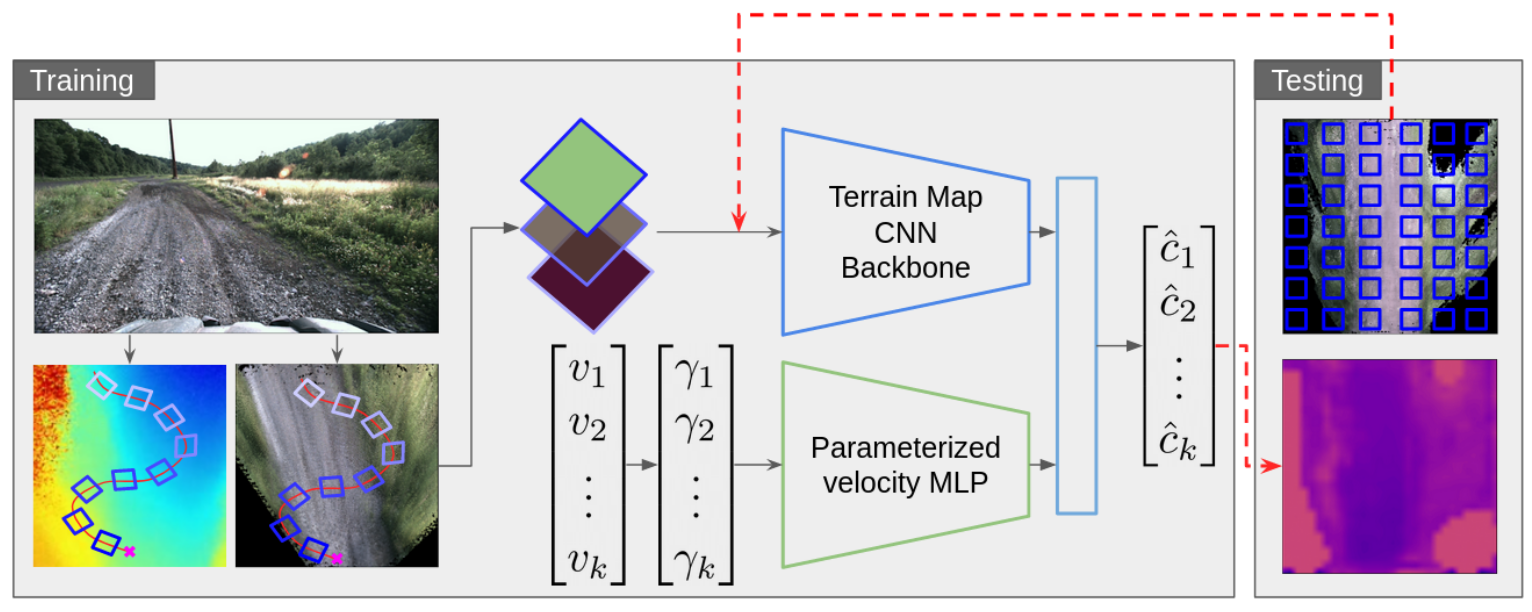
We find that our method outperforms occupancy-based baselines on short-scale and large-scale navigation trials. Our short-scale navigation results show that using our learned costmaps leads to overall smoother navigation, and provides the robot with a more fine-grained understanding of the interactions between the robot and different terrain types, such as grass and gravel. Our large-scale navigation trials show that we can reduce the number of interventions by up to 57% compared to an occupancy-based navigation baseline in challenging off-road courses ranging from 400 m to 3150 m.
Off-Road Driving through Imitating Human Experts
Another source of unlabeled supervision for learning navigation behaviors are examples of teleoperation from human experts. Compared to human labeling of traversable and non-traversable terrain, collecting supervision by simply allowing humans to drive off-road dramatically simplifies and accelerates the data collection process.
In order to translate human-driven trajectories into a form consumable by planning and control, we use inverse reinforcement learning (IRL) to learn costmaps from lidar data. Compared to the alternative of learning actions directly from expert data, learning costmaps has the advantage of being human-interpretable.
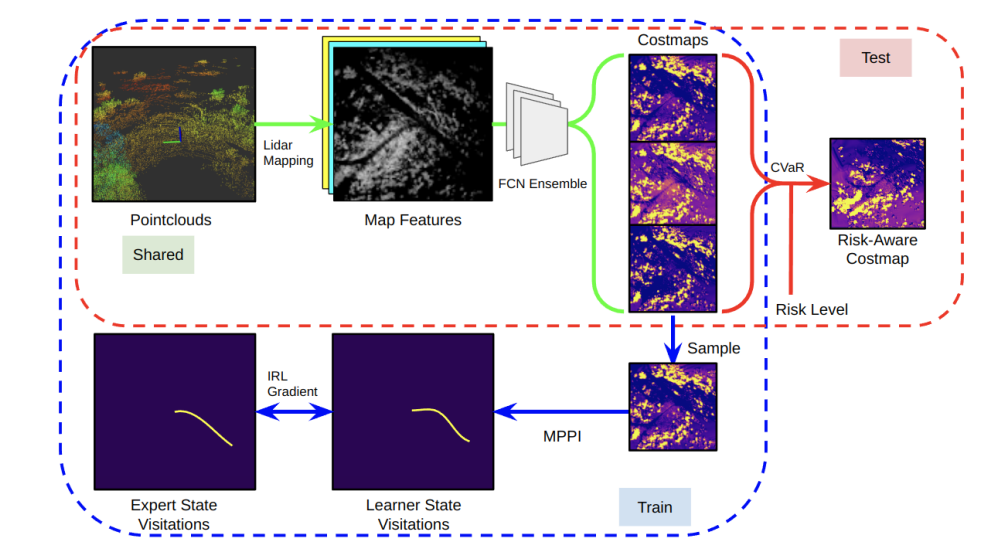
In order to achieve a practical algorithm that runs effectively on our platform, we leverage maximum entropy IRL (MaxEnt IRL) with several extensions, such as sampling-based MPC, risk estimation, and deep neural networks. We find that IRL significantly outperforms occupancy-based baselines on several kilometers of challenging off-road trails (reducing interventions by up to 70%). Furthermore, we find that we can leverage our risk-estimation to modulate how aggressive the ATV is with respect to terrains such as tall grass and slopes. Results are presented in our ICRA 2023 paper “Learning Risk-Aware Costmaps via Inverse Reinforcement Learning for Off-Road Navigation’’.
In addition to using costs as a means of determining where to drive, we also learn a notion of how to drive by learning expert traversal speeds. This enables us to drive at speeds up to 8m/s in open terrain, while driving more conservatively when necessary.
We find that IRL significantly outperforms occupancy-based baselines on several kilometers of challenging off-road trails (reducing interventions by up to 70%). Furthermore, we find that we can leverage our risk-estimation to modulate how aggressive the ATV is with respect to terrains such as tall grass and slopes. Results can be found in our CoRL 2024 paper “Velociraptor: Leveraging Visual Foundation Models for Label-Free, Risk-Aware Off-Road Navigation”.
Learning Vehicle Dynamics
In order to create control rules that guarantee desirable qualities like safety, stability, and generalization of various operating situations, an accurate model of the dynamics of a control system is essential.
The Kinematic Bicycle Model (KBM), one of the examples of a model developed from first principles (purely physics-driven), is widely used in practice but tends to oversimplify the underlying structure of dynamical systems, resulting in prediction errors that cannot be corrected by optimizing over a few model parameters.
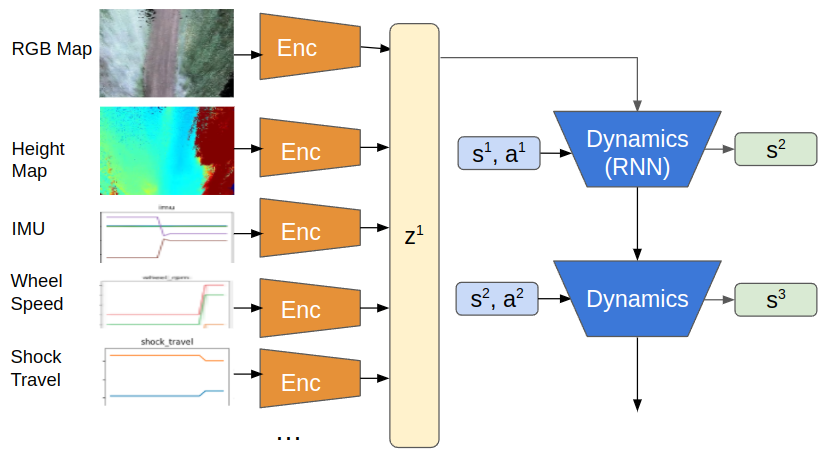
We therefore employ deep learning to address this, which offers very expressive models for function approximation. We leverage real-time information from odometry along with multiple other modalities like, First-Person View Image, Heightmaps and RGB-maps. By reducing the RMSE loss in the anticipated state - [x, y, yaw, velocity] (See Table 1. For deeper analysis), these models outperform purely physics-driven models. Our ICRA 2022 work, “TartanDrive: A Large-Scale Dataset for Learning Off-Road Dynamics Models” provides a thorough description of the model.
Table 1: Here we show RMSE errors of the last predicted point in a 2-second horizon
| x | y | yaw | v | |
|---|---|---|---|---|
| KBM | 1.103 | 0.737 | 0.115 | 1.189 |
| FPV | 0.746 | 0.605 | 0.056 | 0.828 |
| FPV+Maps | 0.528 | 0.488 | 0.054 | 0.598 |
While DL-based models perform better than KBM, they do poorly generalize because they find it difficult to grasp the symmetries and conservation rules that underlie dynamical systems. Consideration of a hybrid method, which encodes physics, laws, and geometric aspects of the underlying system in the construction of the neural network architecture or in the learning process, has been a current study direction in the field and for us. The resulting “physics-informed neural networks” feature superior generalization capabilities, enhanced design, and efficiency. Please check out our paper: “PIAug – Physics Informed Augmentation for Learning Vehicle Dynamics for Off-Road Navigation”.
Online Adaptation for Learning Traversability through Proprioceptive Feedback
Much recent research has focused primarily on improving navigation at the local planning level, in which the challenges of complex unstructured terrain are dealt with at a finer level of detail. Obstacles such as rocks and trees must be detected without being conflated with traversable terrain. Many state-of-the-art approaches instead leverage self-supervised methods in training, using either expert demonstrations or proprioceptive feedback, but often still require a lot of data and can be vulnerable to domain shifts. Ensuring robust performance across a diverse set of environments that themselves inherently change over time requires advanced and adaptive perception.
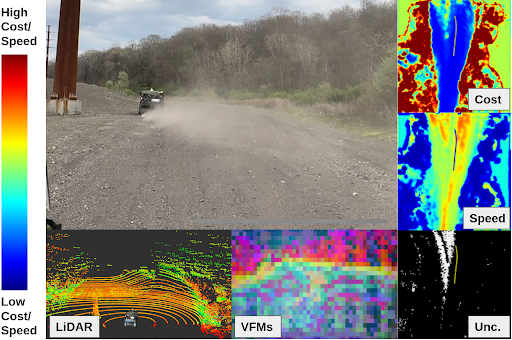
We adopt a philosophy that learned methods for off-road driving should be both self-supervised and adaptive, such that the robot can learn online without a human in the loop. We therefore propose a framework for Self-supervised Adaptive Learning for Off-road Navigation (SALON), which leverages proprioceptive cues and pre-trained visual foundation models to rapidly adjust its understanding of its environment in real-time, eliminating the need for large-scale training data and hand-labels. Specifically, our method predicts costmaps, speedmaps, and uncertainty by associating incoming visual features with roughness experienced by the system. Within seconds of collected experience, our results demonstrate navigation performance with as few interventions as methods trained on 100-1000x more data, while traveling as quickly as possible within the constraints of rider comfort. We additionally show promising results on significantly different robots in different environments. Visit SALON website for more details.

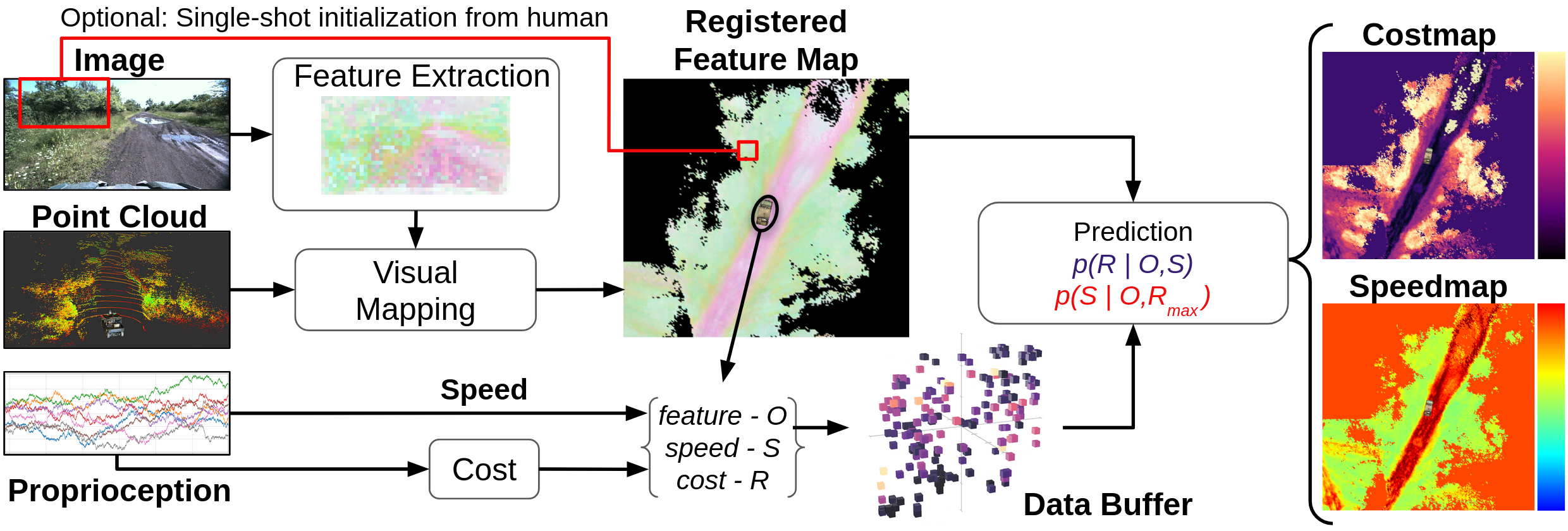
Online Adaptation for Off-road Long-Range Perception
When operating at high speed, the vehicle requires good estimates beyond reactive range (> 30m), for more deliberate and safe navigation. Off-road vehicles will also often operate in new out-of-distribution environments (e.g., desert, forest) or even the same environments with different weather conditions (e.g., sunny vs. cloudy conditions). LiDAR is typically used to build a geometric understanding of the environment to generate traversability estimates. While LiDAR can provide accurate estimates robust to visual appearances, its noise grows as its range increases due to the sparsity of LiDAR points. On the contrary, camera-based methods output dense predictions at further distances. However, typical visual models rely on an immense amount of human-annotated data and perform poorly when the environmental appearance is out of training distribution.
We therefore present ALTER, an Adaptive Long-range Traversibility EstimatoR that adapts on the drive to combine the best of LiDAR and camera to increase the reliable deployment envelope of our perception system, both in range and in environments. Conceptually, we adapt a visual model online from new LiDAR measurements. First, our system labels near-range LiDAR measurements in 3D, then project the 3D labels to image space to produce pixel-wise labels. These labels are used to continuously train new visual models online. By rapidly learning from new measurements, our self-supervised, adaptive approach enables accurate long-range traversability prediction in novel environments without hand-labeling.
We show, within 1 minute of combined data collection and training, our adaptive visual method produces up to 30% improvement in traversability estimation over LiDAR-only estimates and 60% improvement over visual models trained in another environment.
Driving in the Smoke and at Night Time
Multi-Spectral Inertial Odometry
To address the demands of robust operation in harsh degraded visual environments, we developed algorithms using a combination of multi-spectral sensors (RGB cameras and thermal cameras). This combination captures information across both visible and infrared spectra, making it better suited for extreme conditions. Despite the advantages, several challenges must be overcome to fully realize the potential of a multi-spectral combination. We need to address the following key visual challenges:
Low light and low texture: Feature detection and tracking often fail under rapid illumination changes. Existing methods, such as image enhancement, normalization, or data-driven approaches, rely on diverse datasets to improve feature matching. However, these techniques are not directly applicable to thermal images.
Extended darkness: Prolonged darkness, common in disaster scenarios, renders visible-spectrum cameras ineffective. While fusing RGB and depth cameras offers partial solutions, depth cameras have limited range and suboptimal performance. Event cameras have shown promise in low-light settings but depend on continuous motion, making them impractical for search and rescue robots.
Airborne obscurants: Smoke, dust, and snow significantly challenge LiDAR, visual, depth, and event cameras. Thermal cameras offer potential solutions but produce low-quality, noisy images, necessitating advanced feature extraction techniques.
Efficient onboard computation: Deep learning-based visual odometry methods are accurate and robust but require extensive datasets and high computational resources, hindering real-time performance on embedded systems.
Adaptability to environmental changes: Many existing methods use rigid frameworks with fixed feature selection and tracking mechanisms, limiting their adaptability to varying environmental conditions.
To address these challenges, we developed an uncertainty-driven multispectral-inertial odometry (MSO) framework, integrating adaptation from frontend to backend to enhance robustness in extreme visual conditions. MSO is a highly robust and versatile multispectral-inertial state estimator. It is able to overcome low light, low texture, complete darkness, heavy smoke, and their combinations in a single run. The pipeline of MSO details is shown below.
More field tests:
Thermal mapping
To enable robust navigation in visually degraded environments, we developed a thermal voxel mapping module. Traditional thermal imaging provides valuable long-wave infrared information but suffers from low contrast and high noise, requiring specialized processing techniques for effective integration into a mapping pipeline.
To address these challenges, we process 16-bit thermal images through a multi-step enhancement process, including histogram equalization, Contrast Limited Adaptive Histogram Equalization (CLAHE), and bilateral filtering, validated in our previous work, FIReStereo. A colormap is then applied to the processed image for enhanced visualization.
For accurate sensor fusion, we obtain precise extrinsic calibration between thermal sensors and LiDAR using a customized cross-calibration board. Thermal features are then projected onto a voxel-based representation using point clouds from SuperOdometry, enabling real-time thermal mapping in complete darkness.
With future advancements in stereo mapping and deeper integration with MSO, we aim to achieve a fully passive mapping system for autonomous navigation.
Acknowledgments
This work was supported by DARPA and ARL.


